[Linux](Troubleshooting)Slow servers - 2. Diagnose load problems with “top” command
업데이트:
Purpose
It can display system summary information as well as a list of tasks currently being managed by the Linux kernel.
And you can find load problems about CPU, RAM, DISK I/O.
How to use top command
1
cpu core 별 사용률
Shift + p
정렬을 CPU 기준으로 높은 것을 기준으로 상단에 보여진다.
Shift + m
정렬을 Memory 기준으로 높은 것을 기준으로 상단에 보여진다.
Shift + t
정렬을 Time 기준으로 오랜 시간동안 동작한 작업을 기준으로 상단에 보여진다.
Shift + f
화면에 표시된 목록 리스트를 선정하여 원하는 출력을 얻을 수 있다.
Save results to text
top의 전체 출력 결과를 보고 싶거나, 출력을 별도 파일로 저장하고 싶다면 top을 배치모드로 실행하면 된다.
-b : 배치 모드를 활성화
-n : top을 종료하기 전에 배치 모드를 몇번 실행해서 정보를 업데이트할지 제어
- top을 한 번만 실행해 전체 출력 결과를 보고 싶다면
top -b -n 1
- 해당 정보를 top_output.txt 으로 저장
top -b -n 1 > top_output.txt
- top의 출력 결과를 화면으로도 보고 파일로도 기록
top -b -n 1 | tee top_output
You can get the information below
- 시스템이 얼마나 오랫동안 가동되고 있는지
- 평균 부하는 얼마나 되는지
- 실행 중인 프로세스는 몇 개나 되는지
- 전체 / 사용된 / 남아있는 메모리가 얼마나 되는지
Understanding top output information

Cpu(s) : CPU가 현재 하고 있는 일들에 관한 정보를 제공
- us: user CPU Time nice (다른 프로세스에 우선순위를 적용하는 것) 가 적용 되지 않은 사용자 프로세스가 소비한 CPU 사용량을 시간의 비율로 나타낸다.
- sy: system CPU Time 커널과 커널 프로세스의 CPU 사용량을 시간의 비율로 보여준다.
- ni: nice CPU Time nice를 적용한 프로세스가 있을 경우 해당 프로세스의 CPU 사용량을 시간의 비율로 보여준다.
-
id: CPU idle time CPU가 사용되지 않는 유휴 상태의 비율을 나타낸다. 느려진 시스템에서 이 수치가 높게 나타난다면 시스템이 느려진 원인이 CPU 부하 때문이 아니다.
- wa: I/O wait CPU가 I/O를 기다리면서 소비한 시간의 비율을 나타낸 것이다. 이 값이 낮으면 원인을 찾을 때 디스크 혹은 네트워크 I/O 를 확실히 배제할 수 있다.
- hi: hardware interrupts 하드웨어 인터럽트를 제공하는데 CPU가 소비한 시간의 비율을 나타낸 수치
- si: software interrupts 소프트웨어 인터럽트를 제공하는데 CPU가 소비한 시간의 비율을 나타낸 수치
- st: steal time 가상 머신을 실행 중일 경우 이 수치는 가상 머신을 위해 다른 task에서 사용된 CPU 사용량에 대한 시간의 비율을 나타낸 수치다.
1. Check wa value
느려진 시스템을 진단할 때 가장 먼저 확인해야 할 수치 중 하나는 I/O 대기 값(wa)이다.
이 수치를 통해 DISK I/O 를 문제에서 배제할 수도 있다.
I/O 대기가 높다면 무엇이 높은 DISK I/O를 유발하는지 진단이 필요하다.
I/O 대기 시간은 낮고 유휴 시간값(id)은 높다면 시스템이 느려진 원인은 CPU 자원 때문에 발생하는 것이 아니므로 다른 곳에서 시작해야 한다.
높은 입출력 대기 문제 진단하기
높은 I/O 대기 증상을 보았다면 시스템이 대량의 스왑을 사용하고 있는지 확인.
하드디스크가 RAM 보다 훨씬 더 느리기 때문에 시스템에서 RAM이 고갈되고 스왑을 사용하게 되면 시스템은 성능 문제로 고생할 수 밖에 없다.
디스크에 접근하려는 것들은 모두 디스크 I/O 를 위해 스왑과 경합을 하게 된다.
RAM 용량이 충분하다면 어느 프로그램에서 대부분의 I/O 를 사용하고 있는지 확인한다.
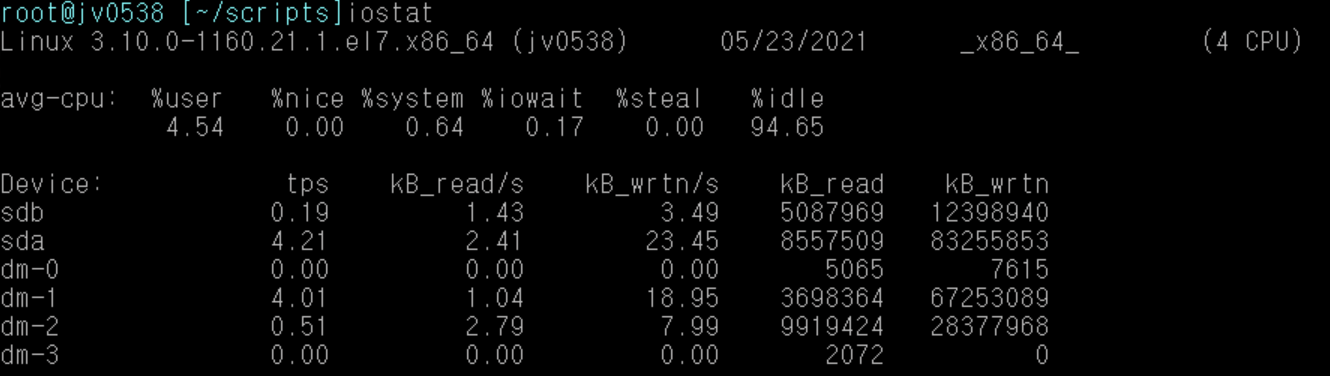
iostat 2 (2초마다 결과 보기)
yum install -y sysstat
CPU
- %user
CPU가 사용자 모드에서 사용된 시간의 비율의 출력값 입니다.
- %nice
작업 우선순위 정책에 의하여 우선순위가 바뀐 프로세서가 사용한 시간의 비율을 출력하값 입니다.
- %system
CPU가 시스템 모드에서 사용된 시간의 비율을 출력한 값 입니다.
- %iowait
디스크의 입출력을 대기하는데 사용된 시간의 비율을 출력한 값 입니다.
- %steal
Steal CPU의 사용시간을 비율로 출력한 값 입니다.
-
%idle
디스크의 입출력을 대기하지 않은 유휴상태의 시간을 출력한 값 입니다.
Disk I/O
- tps
장치에 대한 초당 전송량
- KB_read/s
장치에서 초당 읽혀지는 블록의 수
- KB_wrtn/s
장치에 초당 쓰여지는 블럭의 수
- KB_read
장치에서 읽어들인 전체 블럭의 수
- KB_wrtn
장치에에 쓰여진 전체 블럭의 수
지정된 디스크 장치의 정보 출력
iostat -p /dev/mapper/centos-root

EXAMPLE
백업 작업을 I/O 증가의 원인으로 생각할때
백업 작업은 대개 파일 시스템에서 파일을 읽어 네트워크를 통해 백업 서버에 쓰는 것과 관련돼 있기 때문에
대량의 I/O가 읽기가 아닌 쓰기 때문이었다는 사실을 알 수 있다면
백업 작업에 대한 의심을 배제할 수 있다.
2. Check us value
높은 사용자 시간 (High User CPU Time - us) 진단하기
높은 사용자 CPU 사용률로 일어나는 과부하는 흔히 일어나고 진단하기 비교적 간단하다.
사용자 CPU 사용 시간이 높지만 I/O 대기 시간은 낮은 경우 시스템의 프로세스 중 어떤 프로세스가 대부분의 CPU 자원을 사용하는 확인할 필요가 있다.
3. Check Mem
메모리 고갈 문제 진단하기

Mem
물리적으로 사용 가능한 RAM의 크기, RAM이 얼마나 사용됐는지, 얼마나 여유가 있는지, 얼마나 버퍼로 사용됐는지
Swap
swap 영역에대한 정보, 리눅스 파일 캐시를 위해 RAM이 얼마나 사용됐는지, 리눅스 파일 캐시를 위해 RAM이 얼마나 사용됐는지
- centos7
실제 사용률 = (total-avail) / total
- centos6
실제 사용률 = (total-free-buffers) / total
프로세스가 유휴 상태라면 리눅스는 종종 다른 프로세스가 사용할 RAM을 확보하기 위해 프로세스의 메모리를 스왑 영역으로 옮긴다.
RAM을 사용량 기준으로 정렬
“Shitf + m” command
OOM Killer
리눅스 커널에서는 out-of-memory도 제공하는데, 이것은 시스템이 위험할 정도로 낮은 RAM을 확보한 상태에서 실행되고 있을 때 작동한다.
실제 문제 프로세스 대신 sshd 같은 프로그램이나 다른 프로세스를 대신 강제로 종료시킬 수도 있다.
대부분의 경우 이러한 이벤트중 하나가 발생하고 나면 시스템이 불안정해진다 → 시스템 재부팅 필요
cat /var/log/syslog
에서 로그를 확인할 수 있다.
댓글남기기